

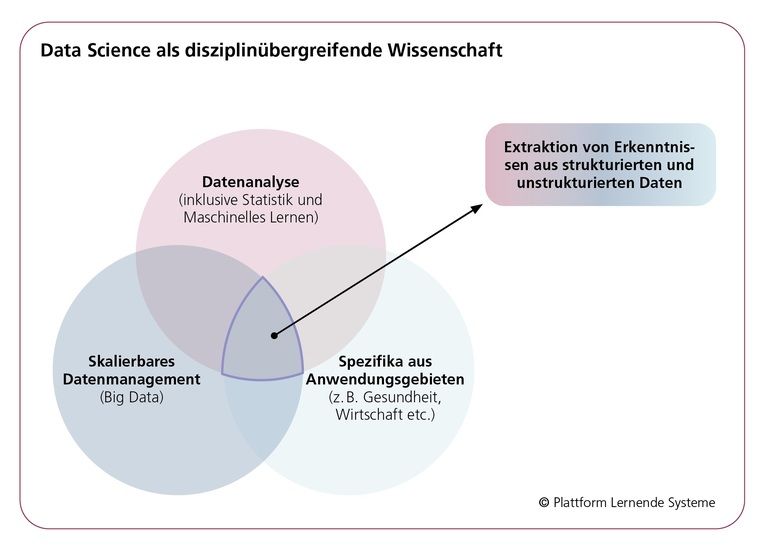
mav: Große Mengen an Daten plus intelligente Algorithmen ergeben nutzbringende KI-Anwendungen. Was ist falsch an dieser Rechnung?
Sattler: Große Datenmengen allein genügen leider nicht. Zwar werden gerade für das Lernen mit tiefen Netzen große Trainingsdaten benötigt, aber dies erhöht natürlich auch den Aufwand bei der Datenerfassung und -vorbereitung sowie beim Training. Daher kommt es darauf an, die richtigen Daten für das Training zur Verfügung zu haben. So sollten die Trainingsdaten – beispielsweise für die Bilderkennung – natürlich die zu identifizierenden Objekte enthalten. Aber eben auch Negativbeispiele in allen möglichen Variationen.
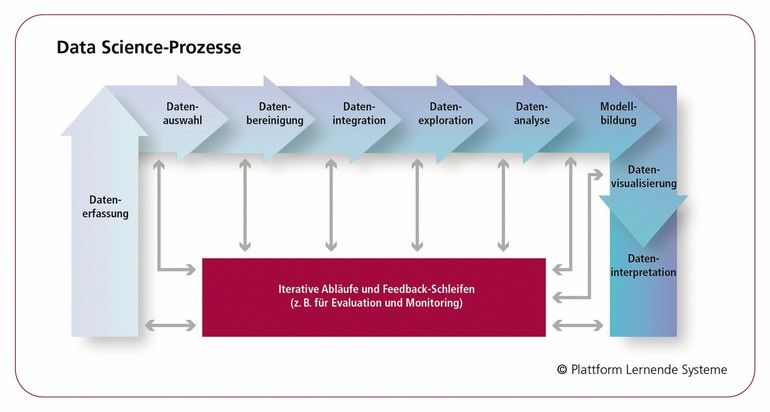
Wie werden Daten zu brauchbaren Daten? Worauf kommt es beim Data Engineering an?
Sattler: Zunächst müssen überhaupt geeignete Daten erfasst werden, die das zu bearbeitende Problem repräsentieren. So sollten für eine Anwendung im Bereich Predictive Maintenance eben auch Fehlerzustände und nicht nur normale Betriebsdaten erfasst werden. Sind Daten erfasst, müssen sie aufbereitet werden. Dies umfasst die Bereinigung wie das Erkennen und Entfernen fehlerhafter Werte, die Verknüpfung mit anderen Daten und gegebenenfalls die Annotation der Daten. Sowohl die Daten als auch die Erfassungs- und Verarbeitungsprozesse sollten dokumentiert und durch Metadaten beschrieben werden, um eine Nachvollziehbarkeit zu gewährleisten. Der Aufwand dieser Vorbereitung kann in KI-Projekten bis zu 80 % des Gesamtaufwands betragen.
Welche Fähigkeiten benötigen Entwicklerinnen und Entwickler, um vertrauenswürdige KI-Anwendungen zu schaffen?
Sattler: Neben Methodenkenntnissen aus dem Bereich des maschinellen Lernens (ML) bzw. der Künstlichen Intelligenz sind dies insbesondere Kenntnisse zur Datenmodellierung, -transformation und -integration, aber auch Kenntnisse der Statistik, um die Eigenschaften der Daten und die Qualität der Ergebnisse bewerten zu können. Ferner sind Kenntnisse aus den Bereichen Ethik und Recht hilfreich, um verantwortungsvoll mit den Daten umgehen zu können. Und natürlich ist auch umfassendes Anwendungswissen unabdingbar.
Es geht also nicht mehr allein um klassische Softwareentwicklung?
Sattler: Nein. Vielmehr sind dies Anforderungen, die einen interdisziplinären Zugang erfordern: Anwendungsexpertinnen und -experten benötigen zunehmend sogenannte Data-Literacy-Expertise und Data-Science-Fachleute müssen auch die Anwendungsdomänen verstehen. Hier wird sich sicher ein großer Bedarf an Weiterbildungsangeboten entwickeln.
Wie können solche Weiterbildungsangebote gerade im Industrieumfeld aussehen? Braucht es Maschinenbauer mit Data-Science-Vertiefung? Oder einen Data Scientist mit Fachrichtung Maschinenbau?
Sattler: Es werden zunehmend Ingenieure benötigt, die datenzentrierte Methoden kennen, verstehen und anwenden können. Dies lässt sich kurzfristig durch geeignete Weiterbildungen, längerfristig aber auch durch entsprechende Studienmodule in klassischen Ingenieurstudiengängen erreichen. Daneben gibt es aber sicher auch Bedarf an Generalisten, also Datenwissenschaftlern, die sich in Anwendungsbereiche einarbeiten können, ähnlich wie das ja schon für Mathematiker, Physiker oder Informatiker gilt.
Kann man dann das Data Engineering und die Modellbildung auch so einfach gestalten bzw. mit speziellen Tools so automatisieren, dass diese auch von Anwendungsexperten durchgeführt werden können?
Sattler: Domänenexperten müssen keine ML-Experten sein, allerdings sollten sie ein Verständnis der Möglichkeiten und Grenzen der eingesetzten Methoden haben. Werkzeuge können hier sicher die Anwendbarkeit unterstützen, aber einen blinden Einsatz von ML-Tools und -Modellen halte ich nicht für ratsam. Gerade dort, wo Modelle erlernt werden, sollte klar sein, auf welchen Daten das Training basiert und welche Features bzw. Parameter verwendet wurden.
Wo liegen gerade in Maschinenbau und Industrie die besonderen Herausforderungen für eine Datenaufbereitung? Ist die Industriewelt etwa besonders heterogen?
Sattler: Die Herausforderungen bestehen zum einen in der Heterogenität – etwa der Vielzahl von verschiedenen Sensoren und Datenaustauschformaten –, aber auch in der Qualität und Menge der Sensordaten. Datenaufbereitung und -bereinigung spielen hier eine wichtige Rolle, Echtzeitverarbeitung großer Datenmengen ebenfalls.
Stehen im Industrieumfeld denn überhaupt bereits alle notwendigen Daten der Maschinen und Komponenten etc. zur Verfügung?
Sattler: Das lässt sich so pauschal nicht beantworten und hängt vom jeweiligen Unternehmen und auch von der Branche ab: Viele moderne Anlagen sind schon vernetzt und bieten die Möglichkeit der Datenerfassung, in anderen Bereichen und Unternehmen steht die Digitalisierung noch an.
Was muss sich ändern, damit das Data Engineering im Maschinenbau einfacher wird?
Sattler: Der Zugang zu Prozessdaten muss vereinfacht werden, z. B. durch Industrie- oder Branchenstandards. Anwenderfreundliche, robuste und domänenspezifische Werkzeuge zur Datenverarbeitung und -analyse werden benötigt, da sich die bei Datenwissenschaftlern beliebten Python-Notebooks nur bedingt für den rauen Industriebetrieb eignen. Und schließlich sollten Domänenexperten mit Data-Science-Kenntnis verfügbar sein.
Wo sind für Data Engineering und KI im Maschinenbau die besonders erfolgversprechenden Segmente?
Sattler: Predictive Maintenance und Anomalieerkennung sind wichtige Bereiche, für die sich bereits Lösungen im Einsatz befinden. Aber auch die Optimierung von Prozessen und der Prozesssteuerung, etwa durch Anpassung von Prozessparametern, bietet großes Potenzial.
Plattform Lernende Systeme
Acatech – Deutsche Akademie der Technikwissenschaften e.V.
www.plattform-lernende-systeme.de
Zur Person
Der Informatiker Kai-Uwe Sattler ist Professor für Datenbanken und Informationssysteme an der TU Ilmenau. Er ist Mitglied der Arbeitsgruppe Technologische Wegbereiter und Data Science der Plattform Lernende Systeme und Co-Autor des Whitepapers „Von Daten zu KI“.








 Handball ist als Mannschaftssport bekannt bei dem es auf jeden einzelnen Spieler ankommt. Beim Zerspanen hochkomplexer Bauteile ist das ähnlich. Von der Idee bis zum fertigen Bauteil bedarf es eines guten Zusammenspiels zwischen technischem Vertrieb, Prozessauslegung, Programmierung und Umsetzung an der Maschine.
Handball ist als Mannschaftssport bekannt bei dem es auf jeden einzelnen Spieler ankommt. Beim Zerspanen hochkomplexer Bauteile ist das ähnlich. Von der Idee bis zum fertigen Bauteil bedarf es eines guten Zusammenspiels zwischen technischem Vertrieb, Prozessauslegung, Programmierung und Umsetzung an der Maschine.

 Im Münsterland gibt es über 4.500 Kilometer ausgeschilderte Radwege, die durch malerische Landschaften und charmante Dörfer führen. Fahrradfahren, ob gemütlich oder mit dem Rennrad, ist hier eine beliebte Freizeitbeschäftigung und ein wichtiger Bestandteil des täglichen Lebens – eine Leidenschaft, die wir bei FOOKE mit Begeisterung leben. Mit unserer Leidenschaft für Präzision und Effizienz in der Metallbearbeitung, inspiriert von der Sportlichkeit und Ausdauer des Fahrradfahrens im Münsterland, freuen wir uns darauf, neue Maßstäbe zu setzen und zu zeigen, was mit modernster Technik alles möglich ist.
Im Münsterland gibt es über 4.500 Kilometer ausgeschilderte Radwege, die durch malerische Landschaften und charmante Dörfer führen. Fahrradfahren, ob gemütlich oder mit dem Rennrad, ist hier eine beliebte Freizeitbeschäftigung und ein wichtiger Bestandteil des täglichen Lebens – eine Leidenschaft, die wir bei FOOKE mit Begeisterung leben. Mit unserer Leidenschaft für Präzision und Effizienz in der Metallbearbeitung, inspiriert von der Sportlichkeit und Ausdauer des Fahrradfahrens im Münsterland, freuen wir uns darauf, neue Maßstäbe zu setzen und zu zeigen, was mit modernster Technik alles möglich ist. Unter dem Motto „From Metals to Medals” nehmen die Auszubildenden von Horn auch in diesem Jahr am Wettbewerb teil. Das Team war für die Planung, Budgetierung, Konstruktion und das eigentliche Fertigen des Projekts verantwortlich. Wie im Sport gilt es, Präzision, Durchhaltevermögen und Leidenschaft zu zeigen.
Unter dem Motto „From Metals to Medals” nehmen die Auszubildenden von Horn auch in diesem Jahr am Wettbewerb teil. Das Team war für die Planung, Budgetierung, Konstruktion und das eigentliche Fertigen des Projekts verantwortlich. Wie im Sport gilt es, Präzision, Durchhaltevermögen und Leidenschaft zu zeigen. Die Skulptur verkörpert die Verschmelzung von industrieller Präzision und regionaler Kultur. Sie symbolisiert die Form des Düsseldorfer Radschlägers – einer Figur, die tief in der lokalen Tradition verwurzelt ist. Die Europazentrale in Willich ist unweit entfernt von Düsseldorf. Die Skulptur besteht aus transparentem Plexiglas. Die kreuzähnliche Form ist mit gebrauchten Sumitomo-Tools besetzt. Diese repräsentieren die Verbindung zwischen der Präzision der Metallverarbeitung und der menschlichen Bewegung beim Radschlagen. Im unteren linken Viertel der Figur bildet ein Kreis aus Schneidplatten den Kopf des Radschlägers.
Die Skulptur verkörpert die Verschmelzung von industrieller Präzision und regionaler Kultur. Sie symbolisiert die Form des Düsseldorfer Radschlägers – einer Figur, die tief in der lokalen Tradition verwurzelt ist. Die Europazentrale in Willich ist unweit entfernt von Düsseldorf. Die Skulptur besteht aus transparentem Plexiglas. Die kreuzähnliche Form ist mit gebrauchten Sumitomo-Tools besetzt. Diese repräsentieren die Verbindung zwischen der Präzision der Metallverarbeitung und der menschlichen Bewegung beim Radschlagen. Im unteren linken Viertel der Figur bildet ein Kreis aus Schneidplatten den Kopf des Radschlägers. Die Wahl beim diesjährigen Kunst trifft Technik-Wettbewerb fiel auf eine Hantelstange,
Die Wahl beim diesjährigen Kunst trifft Technik-Wettbewerb fiel auf eine Hantelstange,











{kind=link}